
Architecture Decision Records are now a first-class resource in EventCatalog. Document the why behind your design choices and link them directly to the services, events, and domains they affect.
Your catalog tells you what services exist, what events they produce, what schemas look like. What it hasn't told you is why any of it was built the way it was.
That's the job of Architecture Decision Records. ADRs capture the reasoning behind significant design choices: why you chose Kafka over RabbitMQ, why the Orders domain owns customer address data, why you split the Payments service the way you did. EventCatalog now supports ADRs as a first-class resource, so that reasoning lives exactly where people go when they need to understand your architecture.
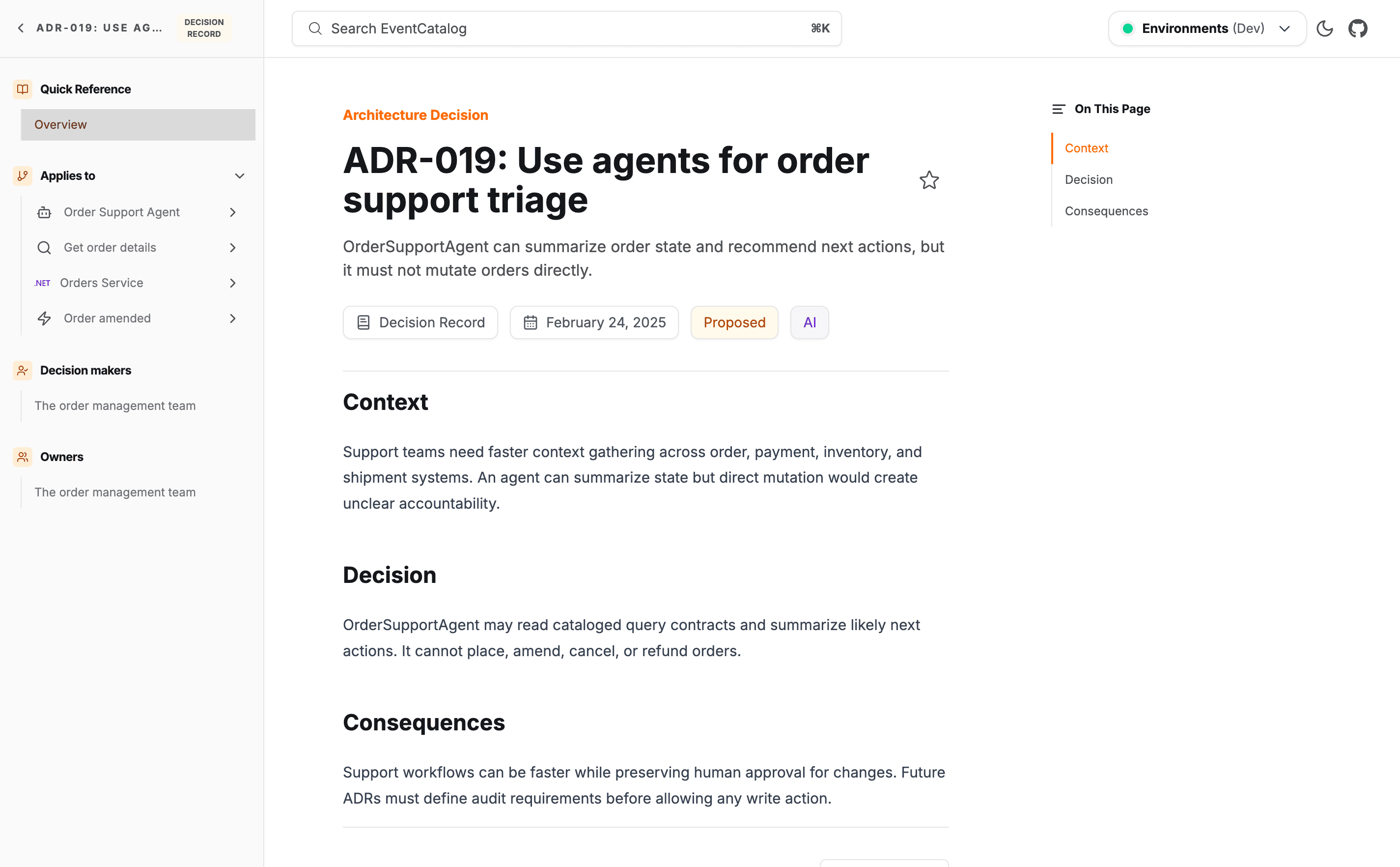
The problem with decisions living somewhere else
Your team documents events, commands, services, and domains in EventCatalog. The decisions behind those things live in Notion, a wiki, a long Slack thread, or a directory of markdown files that nobody remembers to check.
The catalog tells you that PaymentService publishes PaymentProcessed. It doesn't tell you why you made it an event instead of a synchronous call, or why the schema looks the way it does, or what alternatives were considered. That context erodes. Engineers leave. Systems evolve. The original reasoning becomes unreachable.
Decisions separated from the things they describe are decisions that get made again. Usually with incomplete information.
ADRs as a first-class resource
ADRs in EventCatalog work like any other resource: they have frontmatter, versioning, markdown content, and they show up in search, the Discover page, and the visualizer. You write them alongside your other catalog files.
Here is what a minimal ADR looks like:
---
id: adr-001-choose-event-driven-orders
name: Use Event-Driven Architecture for Orders domain
version: 1.0.0
status: accepted
date: 2026-05-26
decisionMakers:
- dboyne
- engineering-leads
---
## Context
The Orders domain needed to communicate status changes to multiple downstream consumers (Inventory, Notifications, Analytics) without tight coupling. A synchronous REST approach was considered but created brittle point-to-point dependencies.
## Decision
We will use an event-driven approach. The `OrdersService` will publish domain events (`OrderPlaced`, `OrderShipped`, `OrderCancelled`) to a shared Kafka topic. Consumers subscribe independently.
## Consequences
- **Positive**: Loose coupling, independent scaling, easy to add new consumers.
- **Negative**: Eventual consistency; downstream systems must handle out-of-order delivery.
The status field supports proposed, accepted, deprecated, and superseded, so you can track a decision through its full lifecycle without losing history.
Read the full ADR guide for the complete frontmatter reference.
Link decisions to the things they affect
The most useful part of ADRs in EventCatalog is the appliesTo field. You can link an ADR directly to the resources it governs: services, events, commands, domains.
---
id: adr-001-choose-event-driven-orders
name: Use Event-Driven Architecture for Orders domain
version: 1.0.0
status: accepted
appliesTo:
- id: OrdersService
type: service
version: latest
- id: OrderPlaced
type: event
version: latest
---
Those links are bidirectional. When someone views OrdersService in the catalog, they see which ADRs apply to it. The decision is discoverable at the point where it matters.
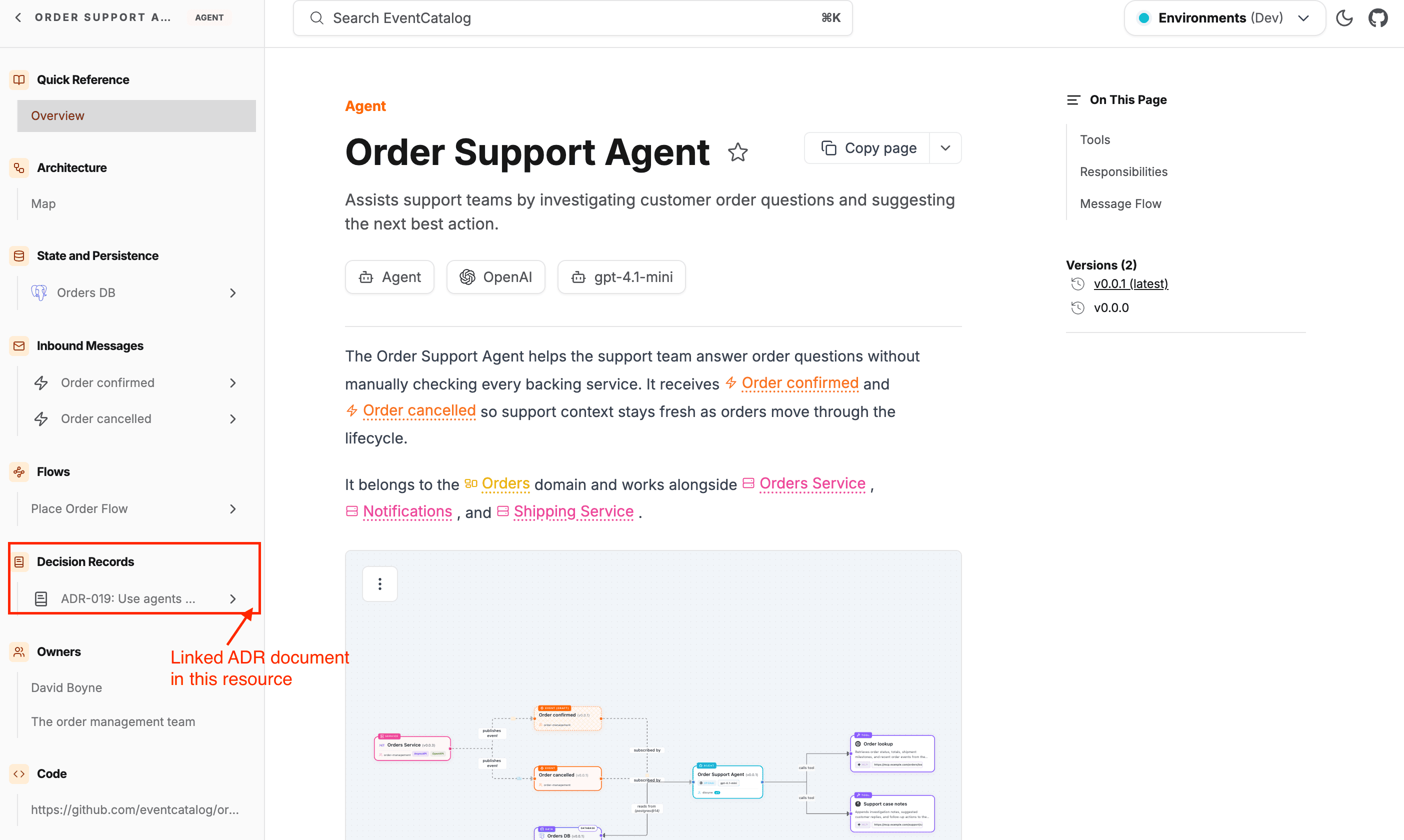
Track how decisions evolve
Decisions aren't static. An ADR accepted in 2023 might be superseded by a different approach in 2025. EventCatalog supports relationships between ADRs through supersedes, amends, and related fields.
---
id: adr-002-kafka-schema-registry
name: Adopt Confluent Schema Registry for Kafka schemas
version: 1.0.0
status: accepted
supersedes:
- id: adr-001-manual-schema-validation
version: 1.0.0
---
The full decision lineage stays in the catalog. You can follow the chain from the original decision to the current state without digging through git history or tracking down the person who made the call.
Discoverable across the org
ADRs appear in the Discover page, filterable alongside every other resource type. Anyone can browse decisions across the whole organization, search by status, or find all ADRs that apply to a given domain.
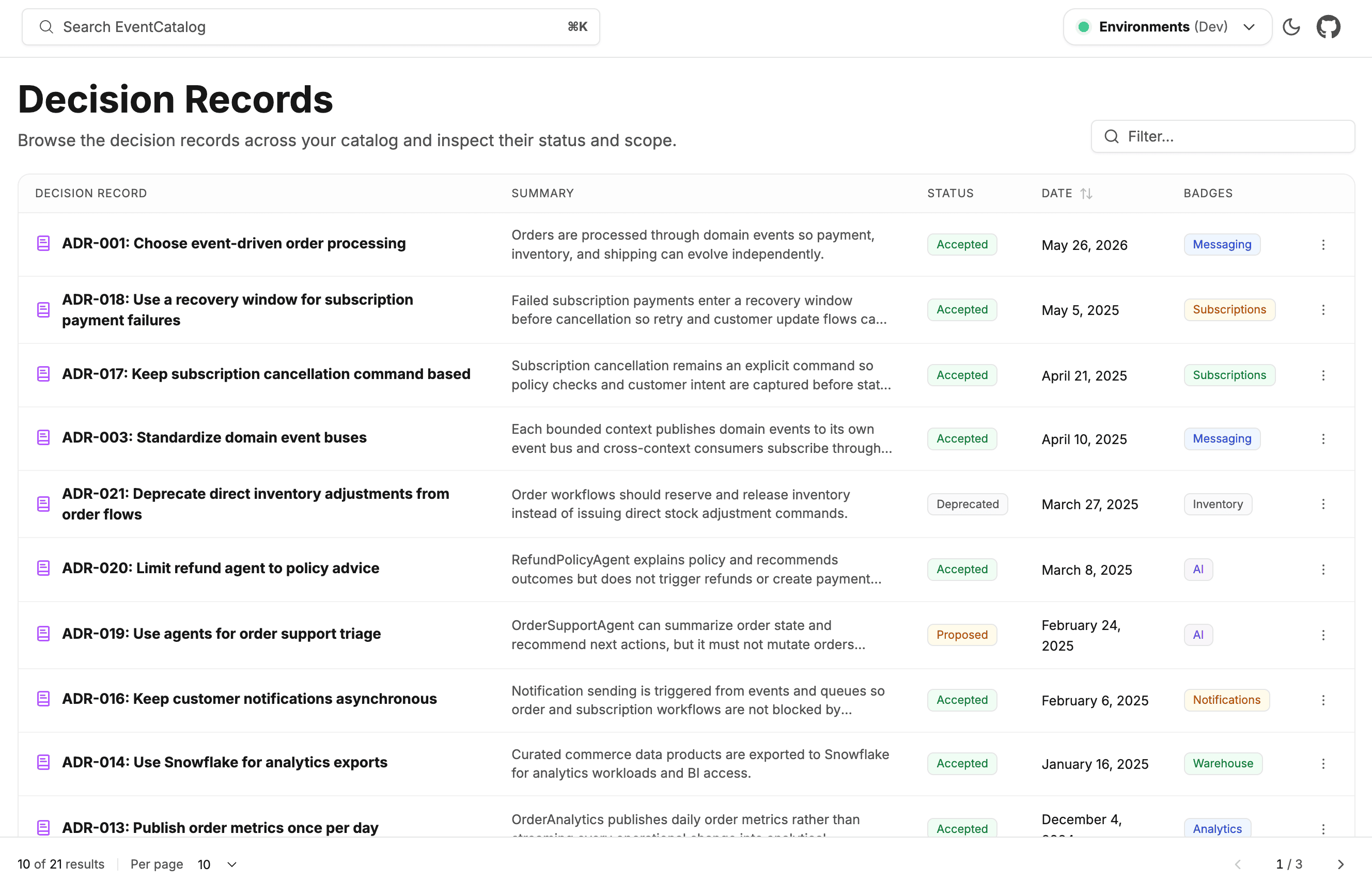
This matters for onboarding. New engineers don't have to ask "why does this look like this?" They can browse the accepted decisions, see what was proposed and rejected, and understand the trade-offs that shaped the system they are now working in.
AI tools can now answer "why"
Because ADRs sit inside EventCatalog, the EventCatalog MCP server exposes them to any AI assistant that supports the Model Context Protocol: Claude, Cursor, Windsurf, and others.
Ask "why did we choose Kafka for the Orders domain?" and the AI reads the actual decision record, not just the code. Ask "what was deprecated in the Payments service?" and it can tell you the status of every ADR that applies to it.
The catalog has always helped with what. With ADRs, it can now help with why.
Try it now
You can browse ADRs in the EventCatalog demo:
To add ADRs to your own catalog, create an adrs/ directory at the root of your EventCatalog project and add an index.mdx file for each decision. The ADR guide walks through the full setup.
Summary
ADRs are now a versioned, linked, discoverable resource in EventCatalog. They connect to the services, events, and domains they affect. They track decision lineage through supersedes and amends relationships. They show up in the Discover page and in the sidebar of every resource they apply to. And they are accessible to AI tools through the MCP server.
The decisions that shaped your architecture should be as discoverable as the architecture itself. Now they can be.
- ADR documentation
- Join the EventCatalog Discord if you have questions or feedback
- GitHub for issues and contributions